Amazon now supports .NET Core in their AWS Cloud solutions.
Together with the AWS Software Development Kit (AWS SDK) for .NET Core, it’s a breeze to create dedicated cloud micro-services. You can find the AWS SDK for .NET Core over here.
To have a quick look at the SDK and what it can do this is an example how to create such a .NET Core Lambda function. Think of a lambda function as a service running somewhere remotely in the AWS Cloud and doing some work for you.
In this example we are going to create a simple Lambda function which will download an XML file and store it in Amazon S3 Storage. Another service might want to read this data back from the S3 Storage. For demo purposes we keep the example simple.
What do we need to do?
- Create the C#.NET Core Lambda code
- Upload the code as a lambda function
- Configure the Lambda for execution
Create the C# .NET Lambda code
After installing the AWS Installer you can create a sample .net AWS project as explained here.
In the project there will already be a AWS generated lambda function class. This class does not have any code yet, it’s just a generated entrypoint for the code. We are going to build two classes that will be used by this function, with two accompanying interfaces to support unit tests for these classes. This is the class diagram after coding up the two classes:
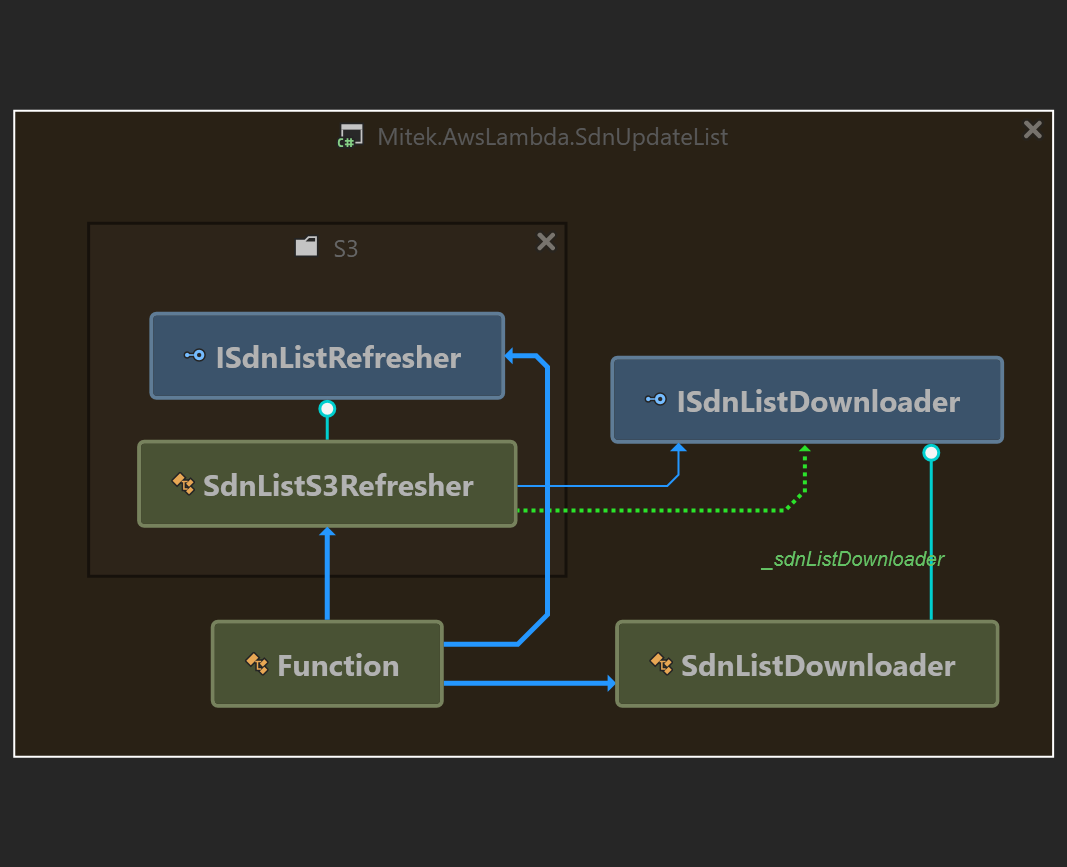
As you can see, apart from the Function class, there are only two relevant classes in the program:
- SdnListDownloader: takes care of downloading an XML file
- SdnListS3Refresher: takes care of putting the downloaded file into an Amazon S3 bucket
The name ‘refresher’ comes from the idea that the function will be executed on generic intervals. On each trigger of the function, the refresher will update the file in the S3 bucket with whatever was the latest retrieved XML file. Basically the solution we are writing ensures that the XML file in the bucket matches the downloaded XML file. Not very fancy, but good for introduction into AWS lambda and generic usage of Amazon S3 storage in the cloud 🙂
The function class itself will instantiate the necessary AmazonS3Client, to be able to tigh everything together. Ok let’s get to the code of the function:
public void FunctionHandler(ILambdaContext context)
{
context.Logger.LogLine($"Beginning process of downloading OFAC Sdn list (usa version)");
try
{
IAmazonS3 s3Client = new AmazonS3Client(); // credentials are setup for the lambda
ISdnListRefresher _listRefresher = new SdnListS3Refresher(s3Client, new SdnListDownloader(context), context);
bool updateSuccess = _listRefresher.UpdateSdnListInDatabase();
context.Logger.LogLine($"Stream processing complete. Result: {updateSuccess}");
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
context.Logger.LogLine(ex.ToString());
throw;
}
}
Writing a lambda is simply writing a method with the name FunctionHandler. That’s it. You are not stuck with that methodname, you can use any methodname you would like however for this example I stick with FunctionHandler. When running in the AWS Cloud, you can provide the name of this method as the starting place of your code.
What you also see is a dependency given of LambdaContext. This lambdacontext is usefull to log some trace-logging information for the lambda. This can be useful for monitoring your lambda function. You don’t have to do anything to inject this context as this is handled by the AWS lambda runner itself, but when deploying the lambda to the cloud you do need to ensure there is a bucket available which receives and stores the log messages.
What the code does is executing an instance of SdnListS3Refresher, which takes an AmazonS3Client and a class that takes care of downloading the source.
For the S3Client, this can be initialized without providing credentials. This is because the client will have the access to the S3 Bucket using the credentials from the Lambda function’s configured Role. A Role is also configured in the cloud. So, not much code, but some configuration to do later on. For now, you can access the created classes from unit tests to test the code on your local system before deploying. Hold on, configuring the lambda comes later.
This is the relevant code for the download class which takes care of reading an xml file. In this example we download the SDN list from OFAC.
So within the SdnListDownloader you will have a method to download the XML file like this:
public string DownloadXmlFileAsString()
{
string url = "https://www.treasury.gov/ofac/downloads/sdn.xml";
try
{
HttpClientHandler handler = new HttpClientHandler()
{
AutomaticDecompression = DecompressionMethods.GZip | DecompressionMethods.Deflate
};
using (var client = new HttpClient(handler))
{
var sdnStream = client.GetStreamAsync(new Uri(url)).Result;
string value;
using (var reader = new StreamReader(sdnStream))
{
value = reader.ReadToEnd();
}
_lambdaContext.Logger.LogLine("SdnList Xml downloaded as string.");
return value;
}
}
catch (Exception ex)
{
_lambdaContext.Logger.LogLine(ex.ToString());
throw ex;
}
}
In this case we’re requesting the file with HTTP Headers: gzip/deflate. When the OFAC server supports compressing the HTTP stream this will save bandwith, as it turns out the SDN.XML file is 7Megabytes, and compressing an XML file with GZip will save a lot of data over the wire…
As you can see, I don’t need to really use an XMLSerializer in this code; the file can be downloaded as one big string.
Next step to downloading the contents of the file is to upload the contents into the S3 Bucket. This is done in the SdnListS3Refresher class described below. The relevant code uses the PutObjectrequest of the AWS SDK Toolkit. As this is the core of putting a file in the S3 bucket using streams, here’s the whole class:
Note that the entrypoint is the method UpdateSdnListInDatabase(), which is called from the Lambda FunctionHandler above.
public class SdnListS3Refresher : ISdnListRefresher
{
private const string BucketName = "yourS3bucket";
private const string S3FileKeyGzip = "sdnlist.gzip";
private readonly ISdnListDownloader _sdnListDownloader;
private readonly IAmazonS3 _amazonS3Client;
private readonly ILambdaContext _context;
public SdnListS3Refresher(IAmazonS3 aS3Client, ISdnListDownloader sdnListDownloader, ILambdaContext context)
{
_amazonS3Client = aS3Client;
_sdnListDownloader = sdnListDownloader;
_context = context;
}
public bool UpdateSdnListInDatabase()
{
string sdnList = _sdnListDownloader.DownloadXmlFileAsString();
if (String.IsNullOrEmpty(sdnList))
{
_context.Logger.LogLine("Download string is empty.");
return false;
}
return PutSdnListAsZipInBucket(sdnList, _amazonS3Client, _context);
}
public static bool PutSdnListAsZipInBucket(string sdnlist, IAmazonS3 s3Client, ILambdaContext context)
{
string puttoBucket = System.Environment.GetEnvironmentVariable("BUCKETNAME");
if (String.IsNullOrEmpty(puttoBucket))
{
puttoBucket = BucketName;
context.Logger.LogLine($"Environment Variable BUCKETNAME not setup, using default: {puttoBucket}");
}
string puttoFile = System.Environment.GetEnvironmentVariable("S3FILEKEYGZIP");
if (String.IsNullOrEmpty(puttoFile))
{
puttoFile = S3FileKeyGzip;
context.Logger.LogLine($"Environment Variable S3FILEKEYGZIP not setup, using default: {S3FileKeyGzip}");
}
try
{
byte[] zip = Zip(sdnlist);
using (var compressed = new MemoryStream(zip))
{
var putJsonRequest = new PutObjectRequest()
{
BucketName = puttoBucket,
Key = puttoFile,
ContentType = "text/xml",
InputStream = compressed,
AutoCloseStream = false,
};
putJsonRequest.StreamTransferProgress += OnStreamTransferProgressEvent;
var resp = s3Client.PutObjectAsync(putJsonRequest).Result;
return true;
}
}
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
public static byte[] Zip(string str)
{
var bytes = Encoding.UTF8.GetBytes(str);
using (var msi = new MemoryStream(bytes))
using (var mso = new MemoryStream())
{
using (var gs = new GZipStream(mso, CompressionMode.Compress))
{
msi.CopyTo(gs);
}
return mso.ToArray();
}
}
private static void OnStreamTransferProgressEvent(object sender, StreamTransferProgressArgs e)
{
Debug.WriteLine("{0}/{1} {2}%", e.TransferredBytes, e.TotalBytes, e.PercentDone);
}
}
The top of the method that does the work of uploading into S3, PutSdnListAsZipInBucket, looks for Amazon Environment variables; this is a way to make the software a little bit more flexible, so that you can still change the bucketname or the storagename of the file after you uploaded the Lambda function binaries into the cloud, without having to continuously update your software.
What this method does: The method will put the data in a (gzipped) stream. The stream will be picked up by the AWS SDK’s PutObjectRequest, which will put the data in the S3 bucket into the given filestorage.
What I found is that the streams that are setup in the using-statements, are automatically closed by the PutObjectAsync request; I first got an exception because of that when running the code, as the using statement in code tries to Displose of the streams, which is already done by AWS SDK.
That’s why the property AutoCloseStream = False is set, so that closing is not done by the amazon provided SDK.
If you are fine AWS SDK controlling your streams, than your code simply should not create the using blocks for the streams. That can also be done of course; the inner part of the method will then look similar to this:
var compressed = new MemoryStream()) // note AutoCloseStream property!
var archive = new GZipStream(compressed, CompressionMode.Compress))
using (var memoryStream = new MemoryStream(Encoding.UTF8.GetBytes(sdnlist ?? "")))
{
memoryStream.CopyTo(archive);
}
var putJsonRequest = new PutObjectRequest()
{
BucketName = puttoBucket, Key = puttoFile,
ContentType = "application/octet-stream",
InputStream = compressed,
AutoCloseStream = true, // or remove as true is the default
};
var resp = s3Client.PutObjectAsync(putJsonRequest).Result;
This way, the MemoryStream / GZipStream are disposed of by the s3Client.PutObjectAsync call; matter of taste; I prefer having control over the streams, prevents another developer thinking streams are not closed…
Enough about the C# Code.. let’s put the solution into the cloud!
Uploading the lambda function
When the coding of the function is done, we can upload the lambda to the AWS Cloud.
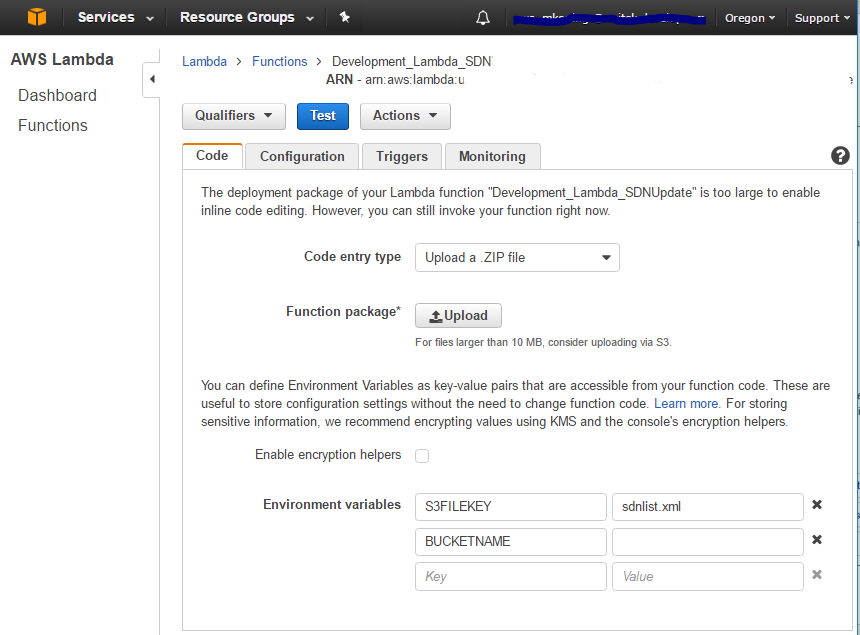
Uploading is a matter of choosing the compile time generated ZIP file, and setting the environment variables that your function is to use. In our case we have several Environment variables to set.
On the Configuration tab, the Handler name is the most tricky part because you have to fully specify the assemblyname, the namespace and classname and the methodname of the lambda to execute. It takes the following form:
Assembly::Namespace.ClassName::MethodName
You also have to chose the Role to use for the lambda. When installing for the first time a default role will be generated whereby logging is enabled.
Uploading the lambda function is explained in more detail here:
http://stackoverflow.com/questions/41292599/error-in-publishing-an-aws-lambda-function-built-in-net-core/41698491#41698491
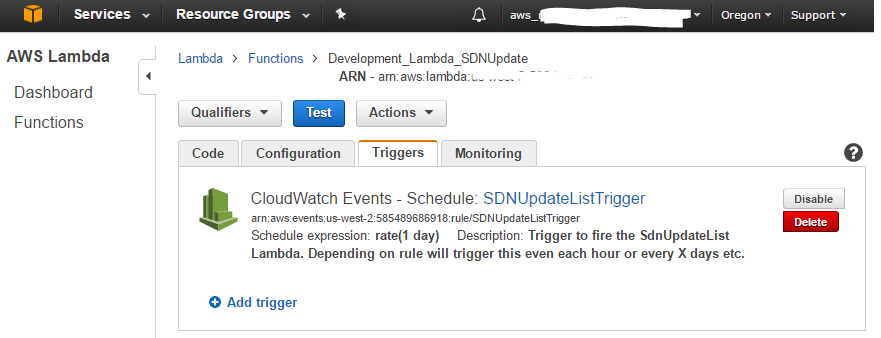
Configure the lambda for execution
To have the lambda temporarily run (every day) a trigger has been defined in the console with a Scheduled timer-task.
After execution; we can find the gzipped sdn.xml file in our S3 cloud bucket!
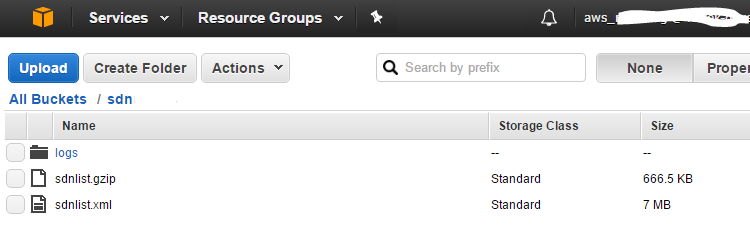
As a test, we also uploaded the sdn.xml as plain xml, just to see the difference in size. Apparently gzipping the sdn.xml saves up to 90% of bandwith when reading/writing to the s3 bucket!
Conclusion
With C#.NET Core you can easily write Amazon Lambda functions that can do cloud operations for you. Uploading and maintaining the functions is as simple as uploading the lambda, setting the Role and giving that role (just) enough access to AWS Cloud functions to do it’s job. Lambda’s are fully scalable; whenever your lambda function would need more processing power, this can be configured and scaled in the cloud. This way, creating multiple of these cloud micro-services can quickly build a fully scalable cloud solution for any operations you would like to perform. Forget maintaining your server farm; move your solutions to the cloud! 🙂